Deep Q-Network
This notebook contains my implementation of a Deep-Q Network, tested within the Cart Pole Gymnasium environment.
This environment can be found here: https://gymnasium.farama.org/environments/classic_control/cart_pole/
In this environment, the robot is tasked with balancing a pole attached at one end to a cart, which is on a frictionless track. Each time step the robot has the option to apply a fixed force to the cart in either the left or right hand direction. These are the only two options, and the robot must choose one each timestep. If the cart exits the arena on either the left or right hand side, or the angle between the pole and the vertical axes exceeds a set value, the episode will terminate. Within this implementation, each timestep the robot receives a reward of +1.
import numpy as np
import gymnasium as gym
from collections import deque, namedtuple
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense, Input
from tensorflow.keras.losses import MSE
from tensorflow.keras.optimizers import Adam
Parameters for the Neural Networks, Experience Buffer, and Learning algorithm.
MEMORY_SIZE = 50_000
STEPS_PER_UPDATE = 4
ALPHA = 0.001
GAMMA = 0.95
TAU = 0.01
BATCH_SIZE = 64
epsilon = 1.0
decay = 0.995
Testing the environment, observation shape, state shape, and number of actions.
env = gym.make("CartPole-v1")
env.reset()
observation_space = env.observation_space
action_space = env.action_space
state_shape = observation_space.shape
num_actions = env.action_space.n
print(f"Observation space: {observation_space}")
print(f"Action space: {action_space}")
print(f"State shape: {state_shape}")
print(f"Number of actions: {num_actions}")
s_prime, r, terminated, truncated, info = env.step(0)
print(f"Next state: {s_prime}")
print(f"Reward: {r}")
print(f"Terminated: {terminated}")
print(f"Truncated: {truncated}")
print(f"Info: {info}")
Observation space: Box([-4.8 -inf -0.41887903 -inf], [4.8 inf 0.41887903 inf], (4,), float32)
Action space: Discrete(2)
State shape: (4,)
Number of actions: 2
Next state: [-0.04720804 -0.24369821 -0.04326152 0.32730305]
Reward: 1.0
Terminated: False
Truncated: False
Info: {}
Feed forward neural networks in the following form:
- State space as input layer
- Dense layer of size 64, ReLU activation
- Output layer of size actions, linear activation
There are two neural networks, as shown in “Implementing the Deep-Q Network”, where one is older and used to calculate the Q-Value for the next state.
inputs = Input(shape=(state_shape))
q_network = Sequential([
inputs,
Dense(64, activation='relu'),
Dense(num_actions, activation='linear')
])
q_hat_network = Sequential([
inputs,
Dense(64, activation='relu'),
Dense(num_actions, activation='linear')
])
optimizer = Adam(learning_rate=ALPHA)
Named tuple for easier tracking and storage of each time-step in the experience buffer. This allows us to index each value as “experience.state” instead of using direct indexes such as “experience[0]”, for easier code readability later on.
experience = namedtuple("Experience", field_names=["state", "action", "reward", "next_state", "terminal_state"])
According to: https://www.tensorflow.org/agents/tutorials/0_intro_rl
Loss for DQN is:
$L_i (\theta_i) = E_{s,a,r,s’~p(.)} [(y_i - Q(s,a,theta_i))^2]$
$y_i = r + \gamma max_{a’} Q(s’, a’, theta_{i-1})$
mini-batch replay is used for experience replay. $x$ transitions are placed into a buffer, then all of these transitions are used to compute loss and gradient
def loss_values(experiences, gamma, q_network, q_hat_network):
# Unpack the replay buffer
states, actions, rewards, next_states, terminal_states = experiences
# Calculate the max Q-value for each state in next_states
max_qsa = tf.reduce_max(q_hat_network(next_states), axis=-1)
# Calculate the TD target, terminal_states stores if end of episode.
# y_i = R if episode terminates next step.
# y_i = R + gamma * max_a' Q(s', a') otherwise
y_targets = rewards + (1 - terminal_states)*gamma*max_qsa
# Get the Q-values for the current states
q_values = q_network(states)
# Find the Q_Values for each state
q_values = tf.gather_nd(q_values, tf.stack([tf.range(q_values.shape[0]),
tf.cast(actions, tf.int32)], axis=1))
# Loss is the mean-squared error of the TD-Error. TD-Error is the TD target minus the current Q-Value
loss = MSE(y_targets, q_values)
return loss
Function that updates $\hat{Q}$ with a soft update from Deep Deterministic Policy Gradient. Equation is found below:
- $\theta^{\hat{Q}} = \tau\theta^{Q} + (1 - \tau)\theta^{\hat{Q}}$
with $\tau « 1$
def update_q_hat(q_network, q_hat_network):
# Update the target network weights based upon the main network weights and TAU value.
for (q_weights, q_hat_weights) in zip(q_network.weights, q_hat_network.weights):
q_hat_weights.assign(TAU * q_weights + (1 - TAU) * q_hat_weights)
Functions which performs the gradient descent used for learning new weights within the Q network.
@tf.function
def learn(experiences, gamma):
# Computes the values for the loss function
with tf.GradientTape() as tape:
loss = loss_values(experiences, gamma, q_network, q_hat_network)
# Compute the gradients of the loss function
gradients = tape.gradient(loss, q_network.trainable_variables)
# Update the weights of the q_network
optimizer.apply_gradients(zip(gradients, q_network.trainable_variables))
# Update the target_q_network weights based upon q_network weights and TAU value.
# Known as a "soft update". used in Deep Deterministic Policy Gradient
# This allows the target network to slowly track the learned network, increasing stability
update_q_hat(q_network, q_hat_network)
Calculates the action based upon a given set of Q values and an $\epsilon$ value in an $\epsilon$-greedy policy.
def action(q_values, epsilon):
# Epsilon-greedy action selection
if np.random.rand() < epsilon:
return np.random.randint(0, q_values.shape[1])
else:
return np.argmax(q_values)
Randomly samples a input experience data set of $BATCH_SIZE$ experiences from the experience buffer, which is then input into the above $learn()$ function
def get_batch(experiences):
# Randomly sample from experience buffer
batches = np.random.choice(len(experiences), size=BATCH_SIZE, replace=False)
# Arrays for each element in the experience tuple for the entire batch
states = np.array([experiences[i].state for i in batches], np.float32)
actions = np.array([experiences[i].action for i in batches], np.int32)
rewards = np.array([experiences[i].reward for i in batches], np.float32)
next_states = np.array([experiences[i].next_state for i in batches], np.float32)
terminal_states = np.array([experiences[i].terminal_state for i in batches]).astype(np.uint8)
# Converts the arrays to tensors
states_tensor = tf.convert_to_tensor(states, dtype=tf.float32)
actions_tensor = tf.convert_to_tensor(actions, dtype=tf.int32)
rewards_tensor = tf.convert_to_tensor(rewards, dtype=tf.float32)
next_states_tensor = tf.convert_to_tensor(next_states, dtype=tf.float32)
terminal_states_tensor = tf.convert_to_tensor(terminal_states, dtype=tf.float32)
# Return the tensors as a tuple.
return (states_tensor, actions_tensor, rewards_tensor, next_states_tensor, terminal_states_tensor)
The code below runs the model on a set number of episodes, $num_episodes$
num_episodes = 2000
max_steps = 1000
episode_rewards = []
memory_buffer = deque(maxlen=MEMORY_SIZE)
q_hat_network.set_weights(q_network.get_weights())
epsilon = 1.0
for episode in np.arange(num_episodes):
# Reset env and reward for current episode
s, info = env.reset()
total_r = 0
for t in np.arange(max_steps):
# Calculate Q-values for the current state
q_values = q_network(np.expand_dims(s, axis=0))
# Epsilon-greedy action selection
a = action(q_values, epsilon)
# Observations of the taken action
s_prime, r, terminated, truncated, info = env.step(a)
# Running sum of rewards for episode
total_r += r
# Append experience to memory buffer
memory_buffer.append(experience(s, a, r, s_prime, terminated))
# Checks every four time steps if the memory buffer has enough experiences, if so update the Q-network
if t % STEPS_PER_UPDATE == 0 and len(memory_buffer) >= BATCH_SIZE:
# Randomly sample from experience buffer and learn from the batch
experiences = get_batch(memory_buffer)
learn(experiences, GAMMA)
# Update state variable for next iteration
s = s_prime.copy()
# End the current episode if the environment terminated or ran out of time
if terminated or truncated:
break
# Decay epsilon until 0.1
if epsilon > 0.1:
epsilon = np.maximum(epsilon*decay, 0.1)
# Track episode rewards
episode_rewards.append(total_r)
# Every 100 episodes print out the reward of the last episode and the average of the last 100.
if episode % 100 == 0:
last_100_average = np.mean(episode_rewards[-100:])
print(f"Episode {episode}, Reward: {total_r}, Last 100 Average: {last_100_average}")
# If the average reward of the last 50 episodes is greater than 225, stop training
if (np.mean(episode_rewards[-50:]) > 225):
last_50_average = np.mean(episode_rewards[-50:])
print(f"Solved with {last_50_average} reward in {episode} episodes!")
break
env.close()
Episode 0, Reward: 15.0, Last 100 Average: 15.0
Episode 100, Reward: 15.0, Last 100 Average: 18.04
Episode 200, Reward: 48.0, Last 100 Average: 28.16
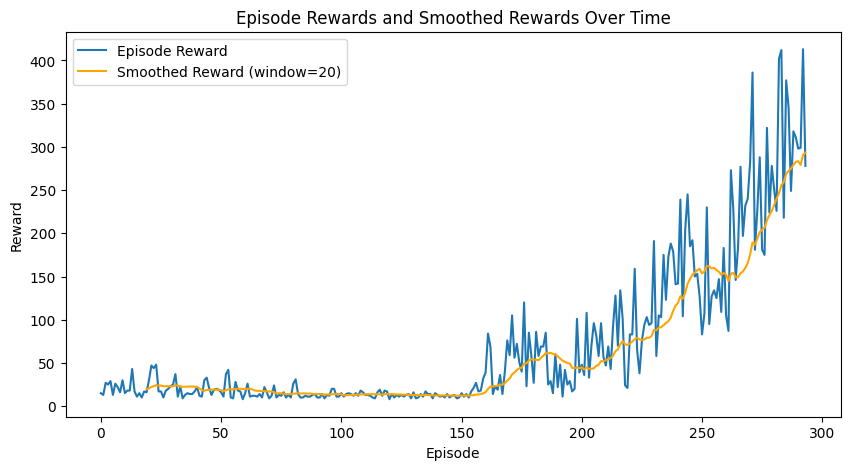
Solved with 226.06 reward in 293 episodes!
The code below simply runs the environment based upon the learned Q-Values. The performance of this should be equal or better than the training runs above, as we are removing the randomness in the action choice from the $\epsilon$-greedy policy.
env = gym.make("CartPole-v1", render_mode='human')
for episode in np.arange(2):
s, info = env.reset()
total_r = 0
for t in np.arange(max_steps):
q_values = q_network(np.expand_dims(s, axis=0))
a = action(q_values, 0.0)
s_prime, r, terminated, truncated, info = env.step(a)
total_r += r
s = s_prime.copy()
if terminated or truncated:
break
env.close()
Below the results over the training are shown.
window = 20
smoothed_rewards = np.convolve(episode_rewards, np.ones(window)/window, mode='valid')
plt.figure(figsize=(10, 5))
plt.plot(episode_rewards, label='Episode Reward')
plt.plot(np.arange(window-1, len(episode_rewards)), smoothed_rewards, label=f'Smoothed Reward (window={window})', color='orange')
plt.xlabel("Episode")
plt.ylabel("Reward")
plt.title("Episode Rewards and Smoothed Rewards Over Time")
plt.legend()
plt.show()