Proximal Policy Optimization, Deep Reinforcement Learning
This notebook contains my implementation of the Proximal Policy Optimization algorithm, tested within the LunarLanderContinuous-v2 Gymnasium environment.
Information about this environment can be found here.
In this environment, the robot is tasked with piloting the lander into the center of a designated landing zone, without the body of the lander contacting the surface. The complete reward function has many factors involved, which can all be found at the above link.
Basic import functions:
import numpy as np
import gymnasium as gym
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torch.distributions import Normal
import matplotlib.pyplot as plt
The cell below implements the Actor network, the Critic network, and the PPOAgent. The actor network outputs a \mu and std for each action dimension, which is then used to create and sample from a normal distribution. The critic network outputs a single value corresponding to the current state. Both networks input the current state vector.
The PPOAgent instantiates an Actor network and a Critic network, as well as a shared optimizer, meant to introduce stability into the training step of the networks. Three additional functions are provided. First, select_action() allows for a state vector to be input, and will input that through the actor network, and sample an action based upon the output. This function returns the action vector, the log probability of that action, and the entropy of the distribution for that action. Second, the compute_gae() function allows for the computation of the generalized advantage estimation for each timestep in the collected batch of experiences, returning a returns vector and an advantages vector. Lastly, the update() function performs the minibatch generation and update loop for the two networks based upon the PPO algorithm.
class Actor(nn.Module):
def __init__(self, state_dim, action_dim, hidden_dim=64):
super(Actor, self).__init__()
self.fc1 = nn.Linear(state_dim, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, hidden_dim)
self.fc3 = nn.Linear(hidden_dim, action_dim)
self.log_std = nn.Parameter(torch.ones(action_dim) * -0.5)
def forward(self, x):
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = torch.tanh(self.fc3(x))
mu = x
std = torch.exp(self.log_std)
return mu, std
class Critic(nn.Module):
def __init__(self, state_dim, hidden_dim=64):
super(Critic, self).__init__()
self.fc1 = nn.Linear(state_dim, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, hidden_dim)
self.fc3 = nn.Linear(hidden_dim, 1)
def forward(self, x):
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
class PPOAgent:
def __init__(self, state_dim, action_dim, lr=3e-4, gamma=0.99, gae_lambda = 0.95, clip_epsilon=0.2, hidden_dim=64):
self.actor = Actor(state_dim, action_dim, hidden_dim)
self.critic = Critic(state_dim, hidden_dim)
self.optimizer = optim.Adam(list(self.actor.parameters()) + list(self.critic.parameters()), lr=lr)
self.gamma = gamma
self.gae_lambda = gae_lambda
self.clip_epsilon = clip_epsilon
def select_action(self, state):
state = torch.FloatTensor(state).unsqueeze(0)
with torch.no_grad():
mu, std = self.actor(state)
dist = Normal(mu, std)
action = dist.sample()
action_clipped = torch.clamp(action, -1.0, 1.0)
entropy = dist.entropy().sum(dim=-1)
log_prob = dist.log_prob(action).sum(dim=-1)
return action_clipped.squeeze(), log_prob.squeeze(), entropy.squeeze()
def compute_gae(self, rewards, values, dones, next_value):
num_steps = rewards.shape[0]
advantages = torch.zeros_like(rewards)
gae = torch.zeros_like(next_value)
for step in reversed(range(num_steps)):
if step == num_steps - 1:
next_val = next_value
else:
next_val = values[step + 1]
delta = rewards[step] + self.gamma * next_val * (1 - dones[step]) - values[step]
gae = delta + self.gamma * self.gae_lambda * (1 - dones[step]) * gae
advantages[step] = gae
returns = advantages + values
return advantages, returns
def update(self, states, actions, log_probs_old, returns, advantages, epochs=4, batch_size=64):
b_states = states.reshape(-1, states.shape[-1])
b_actions = actions.reshape(-1, actions.shape[-1])
b_log_probs_old = log_probs_old.reshape(-1)
b_returns = returns.reshape(-1)
b_advantages = advantages.reshape(-1)
b_advantages = (b_advantages - b_advantages.mean()) / (b_advantages.std() + 1e-8)
dataset_size = b_states.shape[0]
for epoch in range(epochs):
indices = np.random.permutation(dataset_size)
for start in range(0, dataset_size, batch_size):
end = start + batch_size
batch_indices = indices[start:end]
batch_states = b_states[batch_indices]
batch_actions = b_actions[batch_indices]
batch_log_probs_old = b_log_probs_old[batch_indices]
batch_returns = b_returns[batch_indices]
batch_advantages = b_advantages[batch_indices]
mu, std = self.actor(batch_states)
dist = Normal(mu, std)
log_probs = dist.log_prob(batch_actions).sum(dim=-1)
entropy = dist.entropy().sum(dim=-1).mean()
ratios = torch.exp(log_probs - batch_log_probs_old)
surr1 = ratios * batch_advantages
surr2 = torch.clamp(ratios, 1.0 - self.clip_epsilon, 1.0 + self.clip_epsilon) * batch_advantages
actor_loss = -torch.min(surr1, surr2).mean()
values = self.critic(batch_states).squeeze()
critic_loss = F.mse_loss(values, batch_returns)
loss = actor_loss + 0.5 * critic_loss - 0.001 * entropy
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
The function below, run_ppo(), performs the entire training loop of PPO for a given continuous state and action space Gymnasium environment, from collecting the experiences for each batch, computing the advantages, and performing the update loop. Additionally, this will save the final and best performing actor network, or policy.
def run_ppo():
num_envs = 16
env_name = "LunarLanderContinuous-v2"
envs = gym.make_vec(env_name, num_envs=num_envs)
num_mini_batches = 32
state_dim = envs.single_observation_space.shape[0]
action_dim = envs.single_action_space.shape[0]
agent = PPOAgent(state_dim, action_dim, lr=1e-4, hidden_dim=128, gae_lambda=0.95)
state, info = envs.reset()
state = torch.FloatTensor(state)
episode_rewards = []
episode_lengths = []
current_episode_rewards = np.zeros(envs.num_envs)
current_episode_lengths = np.zeros(envs.num_envs)
total_timesteps = 10000000
steps_per_rollout = 4096
num_updates = total_timesteps // steps_per_rollout
num_steps = steps_per_rollout // num_envs
batch_size = steps_per_rollout // num_mini_batches
curr_max = -float('inf')
reward_steps = []
for update in range(num_updates):
states = torch.zeros((num_steps, num_envs, state_dim))
actions = torch.zeros((num_steps, num_envs, action_dim), dtype=torch.float)
log_probs = torch.zeros((num_steps, num_envs))
rewards = torch.zeros((num_steps, num_envs))
dones = torch.zeros((num_steps, num_envs))
values = torch.zeros((num_steps, num_envs))
entropies = torch.zeros((num_steps, num_envs))
for step in range(num_steps):
states[step] = state
with torch.no_grad():
action, log_prob, entropy = agent.select_action(state)
value = agent.critic(state).squeeze()
next_state, reward, terminated, truncated, info = envs.step(action.numpy())
done = np.logical_or(terminated, truncated)
actions[step] = action
log_probs[step] = log_prob
rewards[step] = torch.FloatTensor(reward)
dones[step] = torch.FloatTensor(done)
values[step] = value
entropies[step] = entropy
current_episode_rewards += reward
current_episode_lengths += 1
state = torch.FloatTensor(next_state)
# print(state.shape)
# print(states)
for env in range(num_envs):
if done[env]:
episode_rewards.append(current_episode_rewards[env])
episode_lengths.append(current_episode_lengths[env])
current_episode_rewards[env] = 0
current_episode_lengths[env] = 0
with torch.no_grad():
next_value = agent.critic(state).squeeze()
rewards = (rewards - rewards.mean()) / (rewards.std() + 1e-8)
advantages, returns = agent.compute_gae(rewards, values, dones, next_value)
agent.update(states, actions, log_probs, returns, advantages, epochs=10, batch_size=batch_size) # Remove normalization here
avg_reward = np.mean(episode_rewards[-100:]) if len(episode_rewards) >= 100 else np.mean(episode_rewards)
if (update + 1) % 10 == 0:
print(f"Update {update + 1}/{num_updates}, Average Reward: {avg_reward:.2f}, Episodes: {len(episode_rewards)}, Total Timesteps: {(update + 1) * steps_per_rollout}")
if (avg_reward > curr_max) and (avg_reward > 225):
curr_max = avg_reward
torch.save(agent.actor.state_dict(), "ppo_actor_lunar_lander_continuous_best.pth")
print(f"New best model saved with average reward: {curr_max:.2f}")
if avg_reward >= 275:
print(f"Solved in {update + 1} updates!")
break
envs.close()
torch.save(agent.actor.state_dict(), "ppo_actor_lunar_lander_continuous.pth")
reward_steps = episode_rewards
return reward_steps
plot_rewards = []
if __name__ == "__main__":
plot_rewards = run_ppo()
In the cell below, the function run_trained_agent() allows for us to visually see the performance of our trained policy from the above cell.
def run_trained_agent():
env_name = "LunarLanderContinuous-v2"
env = gym.make(env_name, render_mode="human")
state_dim = env.observation_space.shape[0]
action_dim = env.action_space.shape[0]
agent = PPOAgent(state_dim, action_dim, hidden_dim=128, gae_lambda=0.95)
agent.actor.load_state_dict(torch.load("ppo_actor_lunar_lander_continuous_best.pth", weights_only=True))
state, info = env.reset()
state = torch.FloatTensor(state)
for i in np.arange(10):
env.reset()
done = False
ep_reward = 0
while not done:
with torch.no_grad():
action, _, _ = agent.select_action(state)
random = np.random.uniform(low=-1.0, high=1.0, size=action.shape)
# next_state, reward, terminated, truncated, info = env.step(random)
next_state, reward, terminated, truncated, info = env.step(action.numpy())
done = terminated or truncated
state = torch.FloatTensor(next_state)
ep_reward += reward
# time.sleep(0.1)
print(f"Episode {i+1}: Reward = {ep_reward}")
env.close()
if __name__ == "__main__":
run_trained_agent()
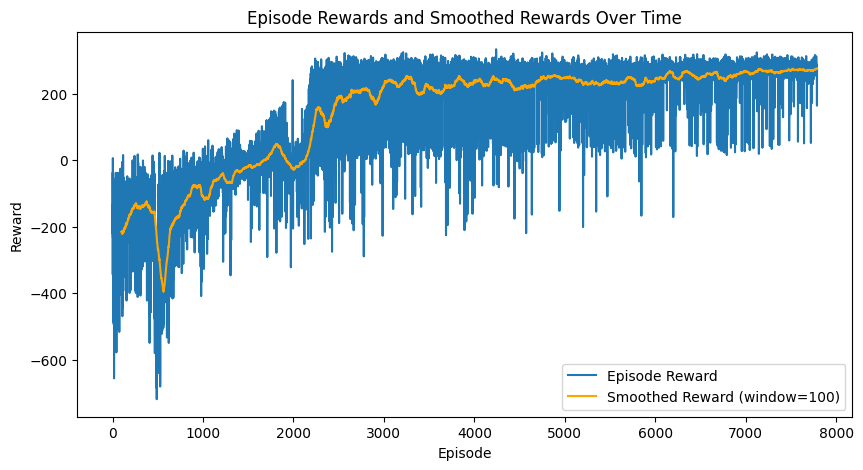
Below is the code and associated plot for the reward for each episode during training. The official barrier for an episode to be considered a solution is to reach +200 reward. In my training, I wanted my agent to perform better, so I had the model train until it was able to average +275 reward over the last 100 episodes.
window = 100
smoothed_rewards = np.convolve(plot_rewards, np.ones(window)/window, mode='valid')
plt.figure(figsize=(10, 5))
plt.plot(plot_rewards, label='Episode Reward')
plt.plot(np.arange(window-1, len(plot_rewards)), smoothed_rewards, label=f'Smoothed Reward (window={window})', color='orange')
plt.xlabel("Episode")
plt.ylabel("Reward")
plt.title("Episode Rewards and Smoothed Rewards Over Time")
plt.legend()
plt.show()